머신러닝 프로젝트의 절차와 특징(WIP)
2024년 2월 1일
목차
머신러닝 프로젝트의 절차
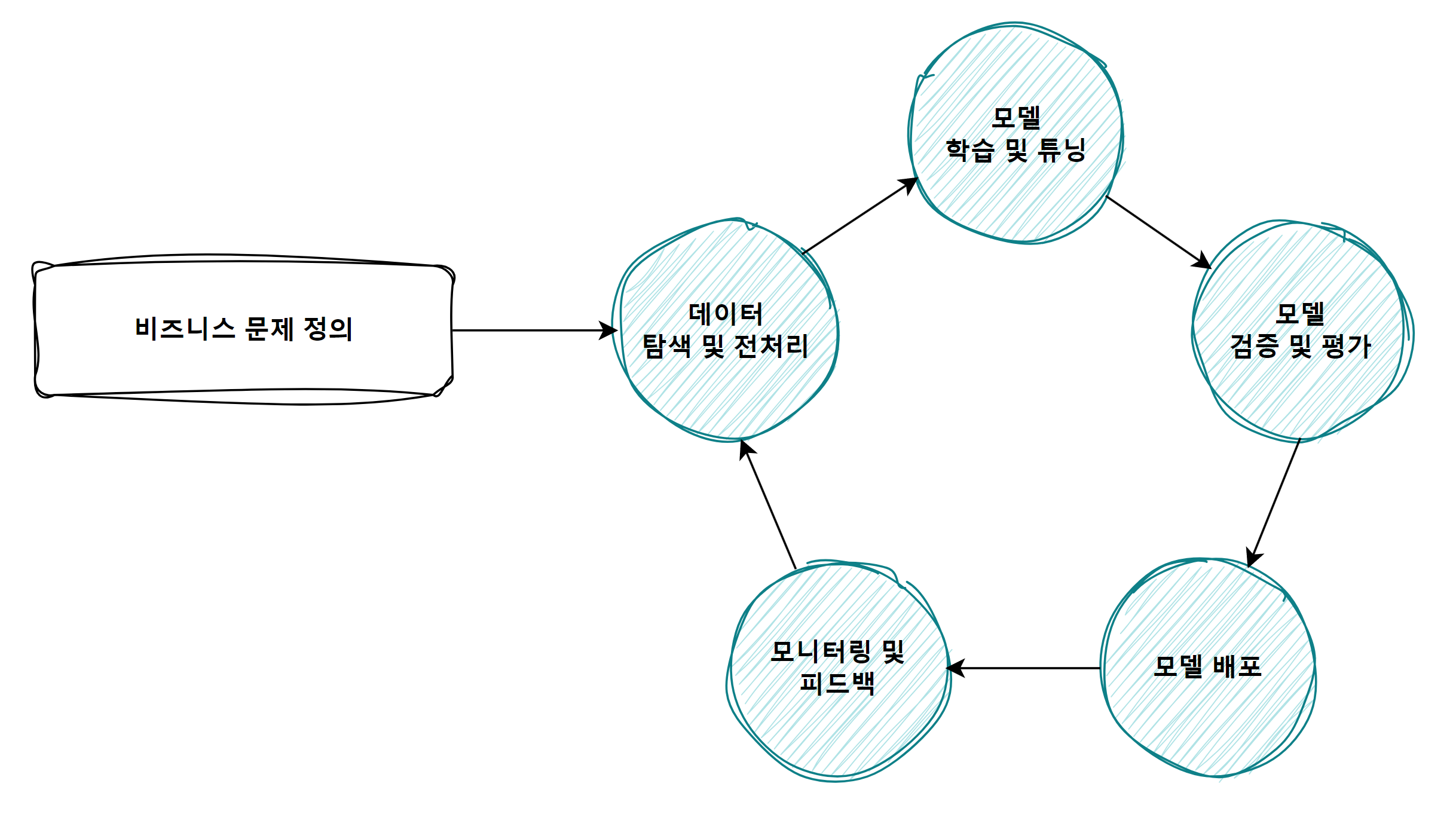
[ 머신러닝 프로젝트의 절차 ]
머신러닝 프로젝트는 비즈니스 문제 정의로부터 시작됩니다. 비즈니스 문제(목표)가 무엇인지 정의하고, 이 문제가 머신러닝 기술으로 해결하기에 적절한지 먼저 판단해야 합니다. 여기에서 중요한 점은 이 적절한 지에 대한 판단을 하기 위해서는 머신러닝 프로젝트의 절차와 특성에 대해 잘 이해하고, 거기에서 발생하는 문제와 비용들을 추측할 수 있어야 합니다.
예를 들어, 다음과 같은 예시가 있습니다.
CASE 1. 해당 문제를 해결할 수 있는 간단한 구현이나 알고리즘이 존재하는 경우
- 이 경우와 같이 명확하고 비용효율적인 방식이 있다면 굳이 머신러닝을 활용할 필요가 없습니다.
CASE 2. 해당 문제가 머신러닝 활용에 적합한 태스크이지만 규모와 비용에 대한 추산이 어려운 경우
- 이 경우에는 프로젝트가 진행 되더라도 예산이나 각종 리소스 문제로 인해 프로젝트가 실패할 가능성이 높아집니다.
- 머신러닝 프로젝트의 규모나 비용을 추산하기 어려운 경우는 주로 의사결정권자 및 이해관계자들이 머신러닝 프로젝트의 절차와 특성에 대한 이해도 부족으로 인해 발생하게 됩니다.
따라서 우리는 MLOps 이전에 머신러닝 프로젝트의 절차와 특성을 면밀히 살펴보고 이해할 필요가 있습니다.
비즈니스 문제 정의
앞서 살펴봤듯이 머신러닝 프로젝트는 진행에 앞서 비즈니스 문제를 정의하고 적절성을 판단해야 합니다. 이러한 과정은 주로 직무 전문가(SME, Subject Matter Expert)가 수행하게 되는데 조직 구성에 따라 수행 주체는 달라질 수 있습니다. 직무 전문가는 달성해야 하는 비즈니스 목표를 제시하고 프로젝트의 적절성을 판단하는 역할을 합니다.
예를 들어, 다음과 같은 비즈니스 목표를 제시할 수 있습니다.
- 이번 분기에 재구매율을 10% 올리겠다. CRM 마케팅을 고도화 할 수 있는 방안이 있는가?
- 이번 분기에 고객 이탈률을 10% 줄이겠다. 상품 추천 시스템을 고도화 할 수 있는 방법이 있는가?
이러한 비즈니스 목표를 먼저 정의해야 하는 이유는 다음과 같습니다.
- 일반적으로 머신러닝 관련 이해관계자들은 비즈니스 관점에서의 이해도는 다소 떨어질 수 있음. 비즈니스 목표가 명확하지 않은 채로 프로젝트를 진행하게 된다면 결과적으로 비즈니스 기여가 낮은 서비스나 모델이 만들어질 가능성이 높음.
- 비즈니스 목표가 명확하지 않으면 문제 해결을 위한 협업 과정에서 많은 어려움이 발생함. 머신러닝 프로젝트는 필연적으로 다양한 직무의 이해관계자들이 협업해야 함. 이해관계자들 간 목표가 일치하지 않는다면 트러블이 발생할 가능성이 높아지고, 이는 곧 프로젝트 실패로 이어질 가능성이 높아짐.
비즈니스 목표 수립을 위해서는 아래와 같은 요소들을 고려해야 합니다.
- 성능에 대한 목표
- 기술 인프라 요구사항
- 비용 제약(프로젝트 기간, 리소스 투입량, 개발/운영/인프라 비용 등)
- ML 프로젝트 전반에 대한 투명성, 설명가능성 수준
또한 직무 전문가는 이러한 비즈니스 목표를 달성할 수 있도록 프로젝트 수행 기간 전체에 거쳐 지속적으로 모델을 평가하고 검증할 필요가 있습니다. 이러한 과정이 필요한 이유는 일반적으로 실험 단계에서의 모델의 학습은 주로 과거의 데이터로 진행하며, 평가는 현실 세계를 반영하기 어렵기 때문입니다. 실험 환경에서 나온 평가 지표들(accuracy, precision, recall, …)이 높다고 해서 실제 사용자에게 반드시 유효하다는 의미가 아닙니다. 실험 환경의 평가 지표들은 높더라도 실제 사용자의 체감 성능은 현저히 낮을 수 있으므로 모델의 정량적 평가 외에도 비즈니스 전문가의 정성적 평가가 필요할 수 있습니다.
직무 전문가는 프로젝트의 적절성을 평가하기 위해 다양한 전략을 취할 수 있습니다. 여기에서 핵심은 “ML 프로젝트 도입 시 비용대비 비즈니스 효용성이 있는가?”를 판단하는 것입니다. 이를 위해서 ML 모델 운영 시 발생할 수 있는 여러가지 리스크에 대해 얼마나 허용할 수 있는지 판단을 해야합니다.
모델 운영 시 발생할 수 있는 리스크에 대한 예시
- 특정 기간 동안 모델을 사용할 수 없는 리스크
- 특정 표본에 대해 잘못된 예측을 반환하는 리스크
- 시간이 지남에 따라 모델 정확도나 공정성이 떨어지는 리스크
- 모델을 유지보수하기 위한 기술 및 리소스가 손실될 리스크
- 예를 들어, 담당 유지보수 인력이 퇴사하는 경우
또 이러한 리스크가 발생할 확률과 영향도에 따른 간단한 평가 매트릭스를 활용할 수 있습니다.

[ 5x5 리스크 평가 매트릭스(Introduce MLOps, O’REILLY) ]
데이터 탐색 및 전처리

[ 데이터 탐색 및 전처리 흐름 ]
데이터 탐색 및 전처리 과정에서는 ML 모델에 적합한 데이터 소스를 식별해야 합니다. 이 과정은 단순해 보이지만 실제로는 꽤 많은 요소들을 고려해야 합니다. 우선 대부분의 머신러닝 프로젝트에서 모델의 성능에 가장 큰 영향을 미치는 부분이 데이터의 품질입니다. 데이터의 품질이 곧 모델의 성능이라고 해도 과언이 아닐 정도로 데이터 품질은 중요합니다. 따라서 적절한 데이터를 식별하고 가공하는 것이 아주 중요합니다.
먼저 리서치 엔지니어 혹은 데이터 사이언티스트는 해결하고자 하는 태스크에 적합한 모델과 선행 연구들을 조사하고, 해당 모델에 필요한 데이터를 식별합니다. 하지만 이들은 비즈니스에 대한 지식과 기업 내에서 생산되는 데이터에 대한 이해도가 다소 부족할 수 있습니다. 따라서 모델에 활용할 수 있는 데이터를 확인하기 위해서는 도메인 전문가 혹은 데이터 엔지니어의 도움을 받아야 합니다.
적절한 데이터를 찾는 과정에서 아래와 같은 체크리스트로 점검해볼 수 있습니다.
- 모델 학습에 사용할 수 있는 데이터 세트가 있는가?
- 해당 데이터 세트는 정확하고 신뢰할 수 있는가?
- 이해관계자들이 해당 데이터에 접근 권한이 있는가?
- 모델에 필요한 특성(Feature)들을 만들어 낼 수 있는가?
- 데이터 라벨링이 필요한가? 라벨링 리소스는 충분한가?
- 특정 기술스택 및 플랫폼 의존성이 있는가?
- 모델 배포 이후 데이터를 어떻게 갱신할 것인가?
- 성과 지표를 어떻게 측정할 것인가?
- 이용약관, 목적성, PII 여부, 법적 검토 등 데이터 거버넌스를 준수 하였는가?
위 과정을 통해 적절한 데이터를 찾았다면 데이터 파이프라인을 점검하고, 필요하다면 데이터 파이프라인을 새로 정의해야 합니다. 이 과정에서는 아래와 같은 데이터 요구사항을 점검해볼 수 있습니다.
- 데이터의 수집 흐름 상 문제가 없는가?
- 데이터의 수집 주기는 적절한가?
- 수집 할 데이터의 양 혹은 기간은 적절한가?
- 데이터가 저장될 위치는 어디인가?
- 전체 워크플로우 예상 수행 시간이 적절한가?
- 실패 혹은 예외 시 발생할 수 있는 리스크와 처리 방안은 적절한가?
이제 다음 단계인 실험 환경에서의 모델 개발을 수행할 수 있습니다.